
WMCTF2020 两道AI相关题目WP
前言
最近忙着搞论文的事情,已经有一段时间没有更新博客了;但是今年的wmctf2020中出现了两道AI相关的题目,吸引了我的目光。本来我是没有准备打这次比赛的,看到群里有大哥在说比赛有机器学习题目,这一下子引起了我的兴趣,不说了,干它就完事。
其实说的两道AI题目,实际用到AI技术的只有第二题。
Performance_artist
题目给出了一张拼接图片,并提示将flag以十六进制的手写形式储存在图片里,所以需要将图片“识别”为对应的数字或字母。
CRC校验
首先,图片显示不全,需要根据crc校验还原其高度,经过还原后的图片:
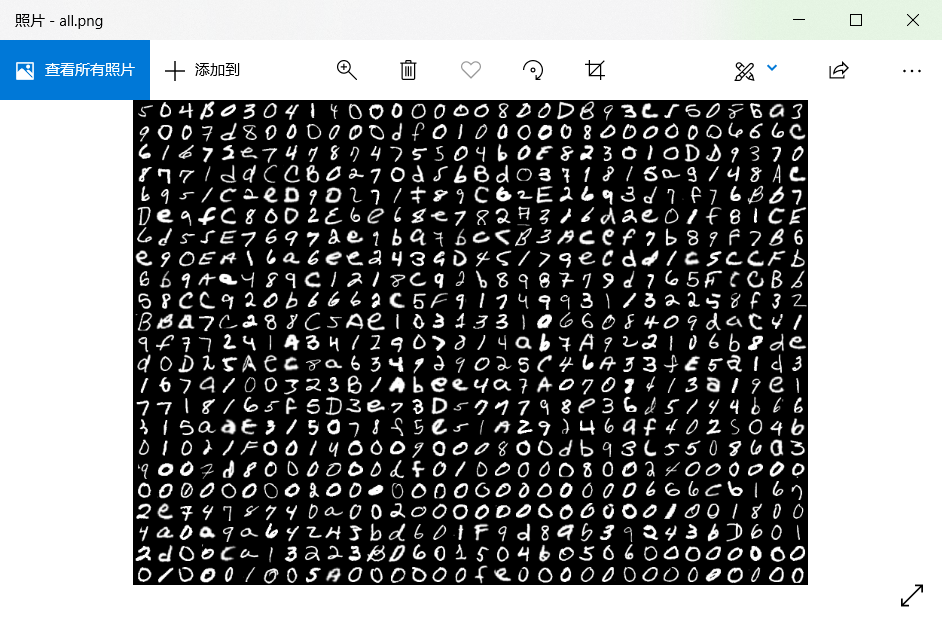
如何“识别”字母
- 接触过机器学习的师傅对mnist数据集一定十分熟悉,这张图一眼就能看出mnist的痕迹,但是mnist是没有字母的。在网上搜了一下,发现是emnist数据集中的字母(mnist数据集的拓展数据集)
- 看到这个图,很多人第一时间想到的是训练一个神经网络来识别,但是神经网络识别跟肉眼识别差不多甚至效果更差,群里已经有师傅肉眼识别过了,发现不太行。这一点也卡了我一些时间。
- 后来一想:这图既然是使用emnist和mnist数据集中的图片拼接成的,那么直接去数据集中寻找标准答案不就可以了吗。
Performance_artist解题过程
- 接下来就好办了,参考mnist和emnist数据集官网的教程,直接下载原数据进行解析。能够读取数据集之后,我将题目中的图片按照像素的16进制储存为字符串,然后同样的,将原数据集中所有图片都存为16进制-label的key-value键值对。然后尝试解析了一下,能出结果了,解析出一个zip。这里有个坑:emnist数据集解析时横纵坐标颠倒了,需要再倒过来才行(这个点有点坑,我被坑了不少时间);解题完整的脚本在本文文末,两个图像字符串化的关键代码为:
|
|
- 直接解压zip,报错说有密码,套娃了,直接伪加密解压成功:
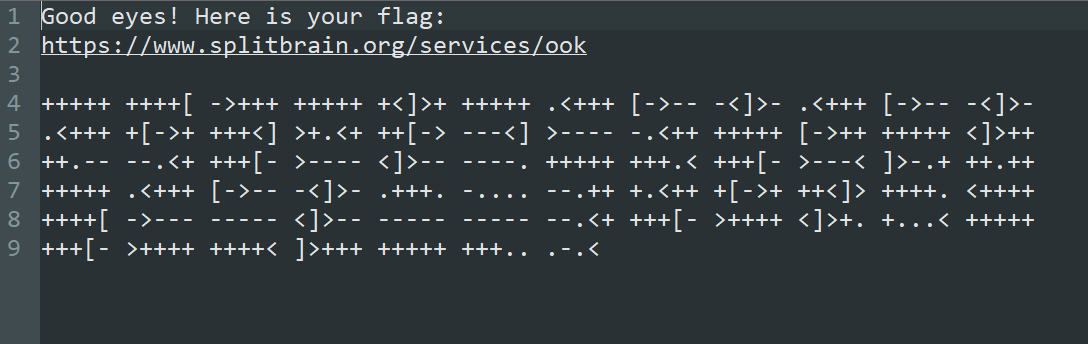
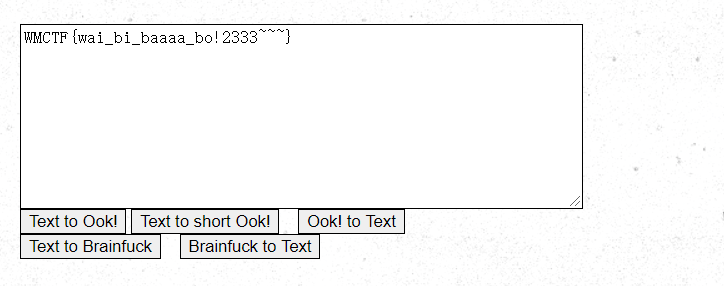
提示brainfxxk编码,解码后得到flag:
总结
此题主要考做题者对机器学习数据集的熟练度,如果对mnist数据集比较熟悉,还是能够想到直接去原数据集找图片的。另外,此题还套娃了几层。
Music_game_2
这道题很有意思,坦克大战移动坦克。我没做 Music_game_1 ,是听群里有师傅说是AI题我才看的。看群里师傅说 Music_game_1 要标准的英式发音来移动坦克走迷宫,感觉挺有意思的。
题目解读
题目给出了一个网页,一个机器学习检测的源码、训练好的机器学习模型和一个left.wav的声音源。机器学习检测源码如下:
|
|
给出的机器学习检测源码是一个将音频分类为上下左右四类的分类器,输出四个类别的概率。并且要求音源与给出的left.wav满足范式:
|
|
还要输出的概率大于90%:
|
|
我们需要通过向网页发送音频文件来移动坦克,使之走迷宫并到达目的地,而后台使用这个机器学习分类器来识别我们给出的音频。意图很明显,我们需要找到left.wav的其他三个方向(上、下、右)的对抗样本,从而移动坦克,属于有目标逃逸攻击。
Music_game_2解题过程
- 由于我之前接触过对抗样本,拿现成的代码来跑是很快的,但是我没做过音频的,此处生成的对抗样本是直接输入机器学习模型的向量。卡在了将对抗样本(mfcc特征)逆向转化为wav文件这步。卡了很久,查了很多资料才发现,最新的librosa库支持mfcc特征逆向转化为wav(就很难受)。接下来尝试fgm有目标攻击,直接调了三个方向的目标,得到了三个对抗样本。经测试,三个对抗样本都满足范式的要求,并且置信度大于90%。
- 接下来到了最兴奋的环境,移动坦克!写个脚本传给网页,移动坦克走迷宫。坦克成功移动了:
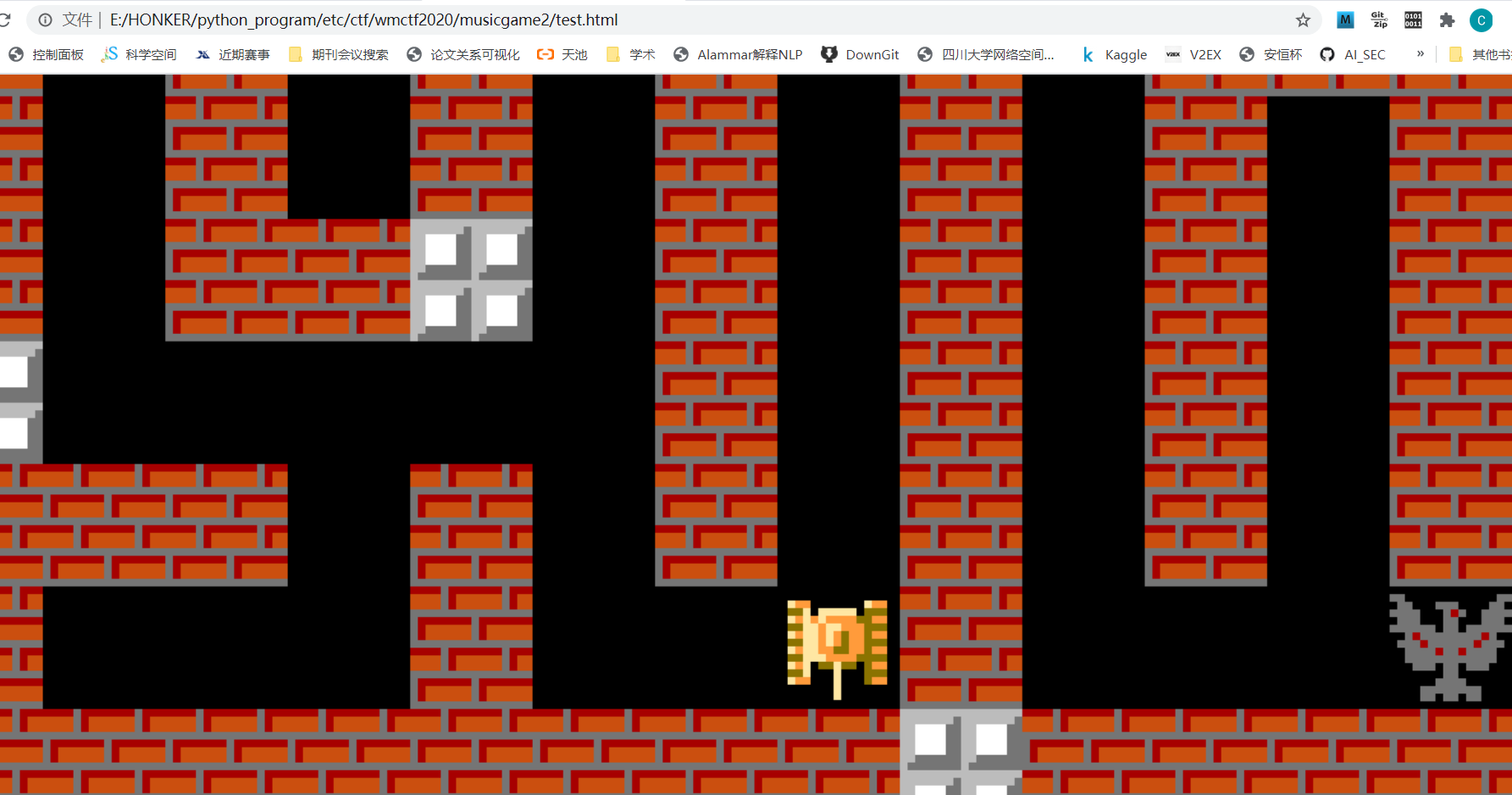
刚开始我还认真数了一张地图的移动次数和方向,但后来发现坦克的地图每个session都不一样,很难受。最后发现目的地总是在地图的右下角,我就先一通绕,最后几步无脑下下下右右右,终于拿到了flag:
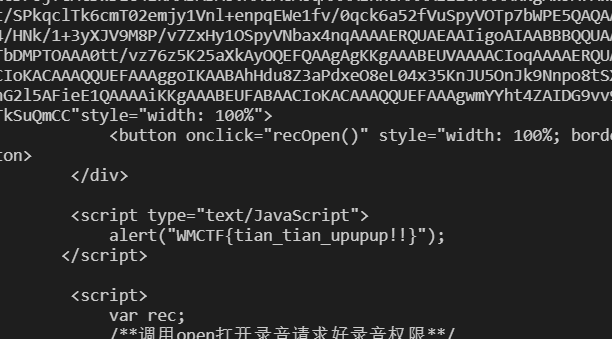
拿到flag的时候比赛已经快结束了,拿了个三血,挺激动的,整个题目的解题脚本在文末给出了地址。
总结
这道题是一道很有意思的题目,结合了坦克大战游戏、Web脚本编写和对抗样本三个元素,游戏的背景让这题很有趣,并且较创新地考察了对抗样本技术。
解题脚本
- 最后,附上这两道AI相关的题目的解题脚本地址:https://github.com/HACHp1/WMCTF2020_MISC_AI_WP