
基于图数据库的静态分析技术初探(一)
近年来,基于图数据库的静态分析技术大火,例如被Github收购的CodeQL已占据安全静态分析的半壁江山。本文浅析相关技术,抛砖引玉。
基本概念
图数据库就是一种使用图结构进行存储和查询的数据库,其中节点和边用于对数据进行表示和存储。
与一般的数据库一致,图数据库的整个概念也重在表达“关系” 借用知乎上的简单例子(见:图数据库是什么? - 星环科技的回答 - 知乎 https://www.zhihu.com/question/310467190/answer/2494375788): 来看一个经典三角恋:从前,有个男人叫小帅,他有个弟弟叫小强,他们有个漂亮的邻居叫小美,他们三个在同一所学校读书。小帅喜欢小美,小强也喜欢小美,但小美不喜欢小强,小美喜欢的人是小帅。
光看这段话,感觉有一堆略复杂的关系,用属性图来表示为:
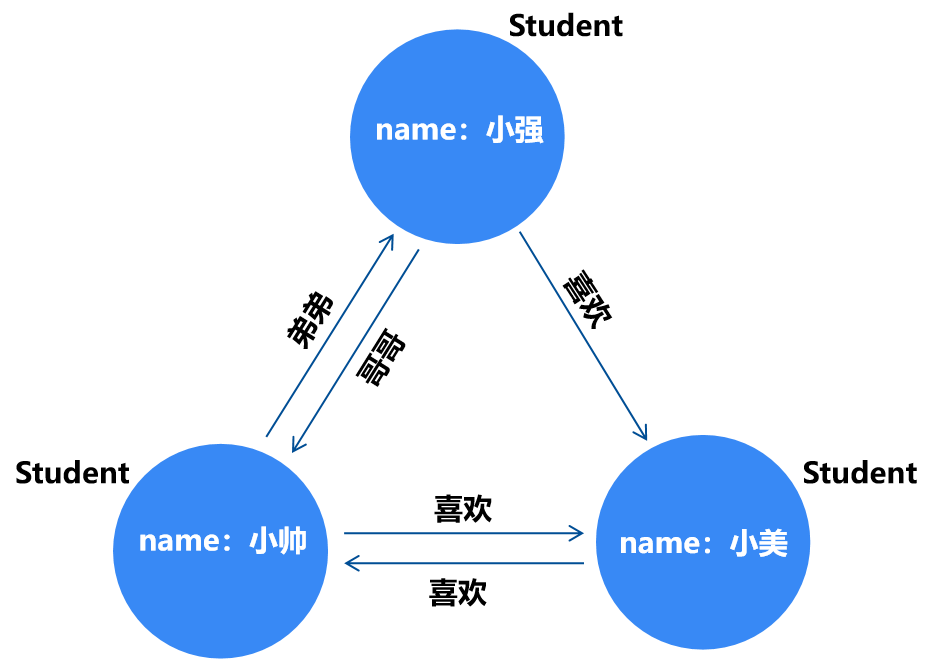
图数据库通常有两大类,一种是属性图,另一种是RDF图;在代码分析上一般都使用属性图。 属性图由顶点(圆圈)、边(箭头)、属性(key:value)组成,在以上的例子中,Student为label,name:xx为property的key和value。 与传统的关系型数据库相比,关系型数据库的一组数据是线性的,而图数据库由结点和边构成,能够表示更为复杂的关系:
以下是3张表:学生、学生选课情况和课程,现在想要查到小美选的所有课程,在线性的关系数据库中查询起来非常麻烦:
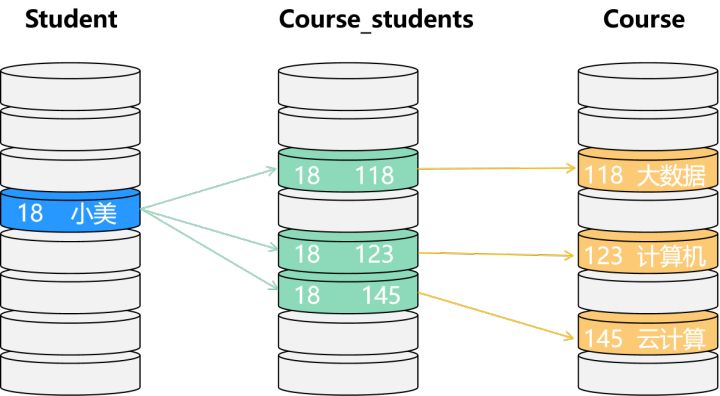
而在图数据库中查询起来十分方便,只需通过”选课“边查询小美结点的连接情况即可:
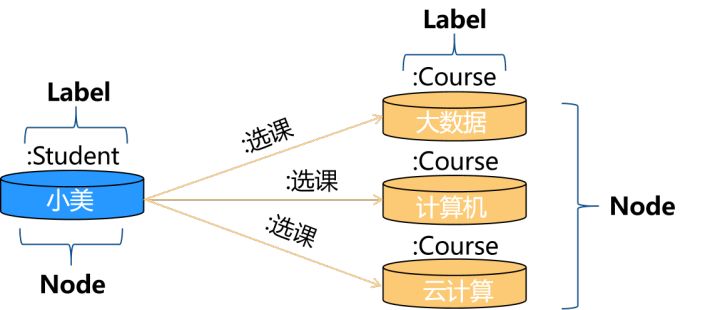
与传统关系型数据库相比,图数据库有以下优势:
- 更好的解释性:用户可以很自然的表达现实世界中的实体及其关联关系(对应图的顶点及边)。
- 更高的检索性能:传统关系型数据库多个表之间连接操作、外键约束,导致较大的额外开销。而图模型固有的数据索引结构,使得它的数据查询与分析速度更快。
- 更灵活:图数据可以表示更复杂的关系结构,图数据灵活的数据模型可以适应不断变化的业务需求,任意添加或删除顶点、边,扩充或者缩小图模型这些都可以轻松实现。
由于有以上优点,最近基于图数据库的静态分析技术大火。
代码属性图
代码属性图,先拆分一下:代码-属性图。代码属性图其实就是用属性图来表示代码。常见的代码属性图有:AST、CFG、DFG、PDG等。 以devign论文中的图为例: 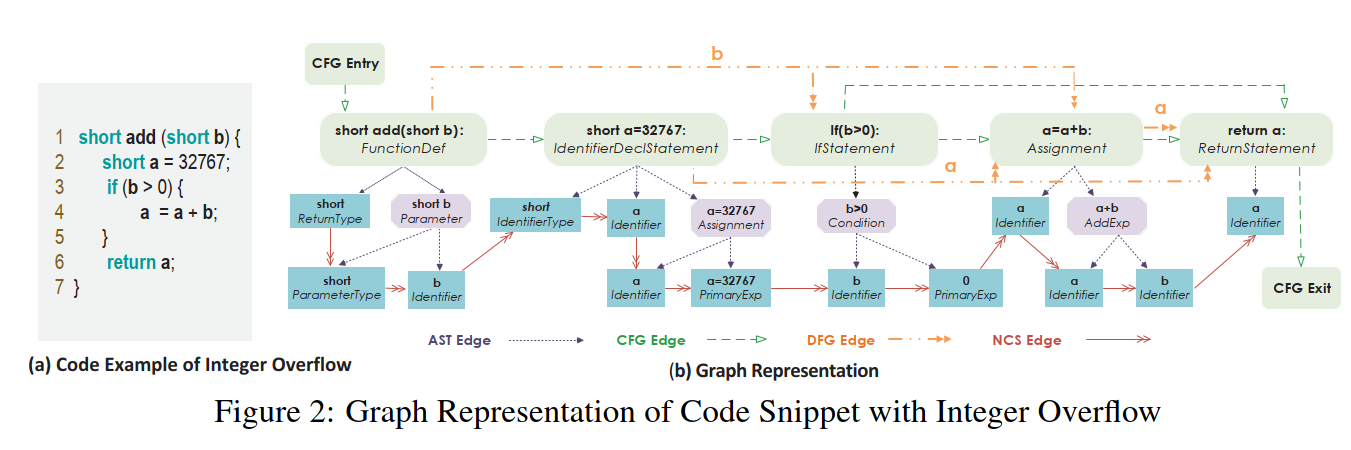 任何一种以某IR(这里的IR是广义的IR,不是必须要三地址码)的属性图来表示代码本身的形式,都可以称为代码属性图。
任何一种以某IR(这里的IR是广义的IR,不是必须要三地址码)的属性图来表示代码本身的形式,都可以称为代码属性图。
基于代码属性图的静态分析,关键在于如何构建代码属性图(包括结点的定义、边的定义)以及如何定义推理/查询过程。代码属性图的定义对应了传统静态分析中的IR的定义,推理过程的定义则对应传统分析中的污点流分析过程。
通常来讲,对于不同特性的语言、不同的需求和场景,需要给出合适的代码属性图定义。
特别的,在Java利用链的挖掘问题下,不仅需要在污点分析阶段(类方法summary)用到基本的代码属性图(CFG),在污点分析结束后,可以将分析结果(一般为类方法的调用关系图)进一步输入到图数据库中,然后由安全人员编写查询语句,以辅助其挖掘调用链。比如BytecodeDL、Tabby。
Datalog
在看代码属性图之前,通过《南京大学软件分析》课程中的内容,先看一下Datalog(作为BytecodeDL的前置知识) 简介:
- Datalog:是声明式编程语言,是Prolog的子集,最初用于数据库,现在广泛应用于程序分析、网络定义、大数据、云计算等。
- Datalog=Data+Logic;Datalog没有副作用(没有赋值)、没有控制流、没有函数、非图灵完备。
相关概念:
- 谓词Predicate:看作一系列陈述的集合,陈述某事情的事实(真假)。如Age,表示一些人的年龄。在真实使用场景下,一般为一个前置条件或一个由条件得到的结论。
- 事实Fact:表示一个组合是否属于一种关系,比如(“Xiaoming”, 18)可以表示“Xiaoming的年龄是18岁”,但注意这个陈述不一定值为True。
以指针分析为例: 首先,我们根据过程内指针分析的4条基本规则,得到以下四种推导关系:
- New(x: V,o: O) <- i: x = new T()
- Assign(x : V, y : V) <- x=y
- Store(x : V, f : F, y : V) <- x.f = y
- Load(y : V, x : V, f : F) <- y = x.f

将这4个推导关系输入datalog引擎,引擎会在数据库中自行推导(进行有收敛地迭代),达到不动点时,即完全指针分析。
实例
- Tabby:字节码->soot->cfg->neo4j->neo4j查询
- BytecodeDL:Soufflé(字节码->soot->cfg)->基于Soufflé(datalog)推理的污点分析->(反序列化链挖掘场景下)neo4j查询
- CodeQL:自己实现的一套将源码转属性图的算法(未开源)->自己实现的一套查询语法(类似于sql)
BytecodeDL
BytecodeDL基于Doop,Doop基于souffle,实际上是在Souffle推理引擎下,使用自己实现的datalog来进行污点分析、类方法调用分析等个性化推理。对于java链子的查找问题,BytecodeDL将类方法的调用关系储存到neo4j中,然后在neo4j中进一步对结果进行筛选、查询。
先来看看souffle(以下例子可在:如何快速上手指针分析工具doop? - 澪同学的回答 - 知乎 https://www.zhihu.com/question/499028330/answer/2473710030 中找到): 可以在http://plang1.it.usyd.edu.au:8000/中执行:
|
|
解释: souffle以.decl edge(n: symbol, m: symbol)的形式来定义关系,symbol为属性的类型(symbol为字符串,此外还有 number);在上面的例子中,定义了两个关系(edge和reachable):
|
|
然后,上例中给出了几个基本条件(facts)用于推理:
|
|
之后,定义了两种推理过程:
|
|
以上表达式,说明由冒号右边可以推理出冒号左边(是不是很想数学的箭头证明),上面的第一句表示,如果x和y由边连接,那么可以推理出x与y可达;第二句表示,如果x和y由边连接,且y和z可达,那么x和z可达。 这个过程其实与数学归纳法一致:
- 归纳奠基:facts
- 归纳推理:以上的推理过程
.output reachable则表示要输出的内容,最后的执行结果: 
BytecodeDL的进一步学习在下一篇文章中进行。
Tabby
主要针对Java各种链(反序列化链、JNDI链等,通常是Java对象可控的情况下挖掘对应的链子)的半自动挖掘。设计了面向Java语言的代码属性图构建方案,包括类关系图、函数别名图、精确的函数调用图。函数别名图将所有的函数实现关系进行了聚合。
CodeQL
自己实现的一套将源码转属性图的算法(未开源)->自己实现的一套查询语法(类似于sql)。
基于代码属性图/Datalog的静态分析技术的特点
优点
- 编写门槛低,易于理解;这也是图静态分析大火的主要原因,只需要编写查询语句/简单的推导语句即可完成污点分析,对于推广来说十分方便。并且基于这个优点,安全人员针对具体场景进行定制化也比较容易。
这一点可以展开说,传统的静态分析工具(基于AST等的)一般是把污点分析过程写死了,只提供给安全人员污点函数和污点本身的自定义化的接口或规则编写接口,灵活度不够。而基于图的分析工具,则把污点传播的过程的定义也交给安全人员,安全人员通过查询语句/Datalog对这个过程进行定制化的编写,这样看来灵活度更大。 实际上,传统基于AST/CFG的静态分析能做到的事情更多(上限更高),但开发门槛太高,不便直接把污点传播过程的定制化交由安全人员处理。但基于Datalog或查询的图静态分析正因为编写门槛低,其定制化过程也不够灵活,外加其固有缺陷,很多过程都无法处理,即使能够处理,查询语句往往也很复杂,脱离了其简洁化的初衷。 方便编写和处理细致程度实际上是一对矛盾,针对不同场景选择合适的方法才是根本。
- 推导速度快(与图数据库一致)
Datalog与图查询对比
- Datalog与图查询相比,Datalog更偏重于类似数学归纳的过程,关注一个子句并将其循环作用在程序上,而图查询更倾向于使用者通过一系列查询语句来描述从源到污点的整个污点流的过程。
- Datalog一般用于做基本的污点分析,可以把分析结果转存为图数据库,然后进行进一步查询和分析,所以Datalog和图查询不是相互替代的 ## 缺陷 基于代码属性图/Datalog的静态分析有以下缺点:
- 表达能力受限,非图灵完备,有的情况处理不了
比如有的时候需要中途去掉一些sinks,Datalog就无法实现,因为推理过程不考虑程序的顺序 再比如表达单个存在很容易,但表达同时满足多个存在比较困难,通常需要双重否定(以下例子中,if中的两个条件要同时满足才能到达污点,而datalog在单次推理时只会输入$a=1或$b=2,要表达“同时”,则需要双重否定:$a!=2或$b!=2的否定):
|
|
- 不能完全控制性能(底层已经实现了,无法再进行优化)