
attention与Transformer结构浅析
前言
- attention机制除了“attention”之外,另一个关键词是“相似度”,阅读attention结构时记住“相似度”这个词。
- 为了对attention模型提出的原因作出解释,我们首先分析RNN的一些特点。
RNN
- 朴素RNN的思想很简单,即把上一步的输出与这一步的输入同时输入新CELL:
\[ \boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t) \]
在这个基础上,出现了RNN的各种变种:LSTM、GRU等
RNN的缺陷
- RNN结构和其变种有明显的缺陷。在时序过长时,最初的神经元传递的信息会逐渐消失,所以RNN适合对短时序的数据进行学习。
attention与Transformer
- attention结构本身不是时序模型而是词袋模型,没有直接使用先后顺序来理解数据,而是从着重点入手,对不同区域的数据给予不同的注意力。由于本身没有在时序上的迭代,在长时序时,attention也可以捕捉到最初神经元的信息。
矩阵乘法的意义
- 在说明attention的计算过程之前,我们首先要理解矩阵乘法的意义。这里以线性组合和矩阵内积两个方面相结合来理解attention机制中的矩阵乘法。
线性组合
- 矩阵乘法的过程,就是把左边的矩阵的列向量按右边矩阵的列向量进行线性组合。同理,如果看作行向量,则是右边的行向量按左边的行向量的线性组合。
- 在attention的计算过程中,连续用到两个矩阵乘法,则直接理解为行向量的线性组合。而线性组合的操作即是“应该”放置“多大”的注意力(按照线性组合的系数放置注意力)
矩阵内积
- 由向量的内积可以推广到矩阵内积,而向量内积有定义:\(|α||β|cosθ\),可以用来衡量两向量的相似性。同理,矩阵内积的大小可以衡量两个矩阵之间行向量与列向量之间的相似性(左行右列)。此处的左行右列也证明了第二个矩阵需要进行转置操作才能衡量行与行之间的相似性。
- 在attention操作的过程中,两矩阵相乘(第二个矩阵经过转置)得到的矩阵即任意两行之间相似度关系的大小。
attention计算过程
- 最原始的attention操作计算的即两个矩阵每行之间的相似程度。attention本身的过程中没有涉及到权重的运算。而实际操作时,attention可以在Q、K、V中涵盖可变的权重,使计算过程更灵活(如:\("Q"=\boldsymbol{Q}\boldsymbol{W}_i^Q\))。下面首先介绍基本的attention结构。
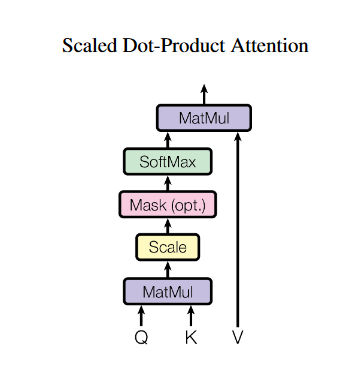
attention的权重的表达式为:
\[ α_i=softmax(s(key_i,q)) \] 其中,\(α_i\)称为注意力分布,\(s(key_i,q)\)为注意力打分机制,常见的有:
\[ 加性模型:s(x_i,q)=v^Ttanh(Wx_i+Uq) \]
\[ 点积模型:s(x_i,q)=x_i^Tq \]
\[ 缩放点积模型:s(x_i,q)=\frac{x_i^Tq}{\sqrt{d_k}} \]
\[ 双线性模型:s(x_i,q)=x^T_iWq \]
论文中采用的计算式为:
\[ Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V} \]
将Q、K、V每一行向量拆开看,可以很容易看出三个向量之间连续使用了两个点积计算,前面说过,点积计算的是两个向量之间的相似程度:
\[ Attention(\boldsymbol{q}_t,\boldsymbol{K},\boldsymbol{V}) = \sum_{s=1}^m \frac{1}{Z}\exp\left(\frac{\langle\boldsymbol{q}_t, \boldsymbol{k}_s\rangle}{\sqrt{d_k}}\right)\boldsymbol{v}_s \]
- 在原论文中说明,在高维度点乘的过程中,输出的数据会很大,再经过softmax映射后,就呈现出接近0和1的趋势(而没有类似于0.5的过度),失去了softmax的概率映射的意义,所以除以\(\sqrt{d_k}\)。
- 忽略掉\(\sqrt{d_k}\),可以很容易体会到attention的过程,Q、K、V分别代表query, keys, values。首先,函数通过一个矩阵乘法操作\(\boldsymbol{K}\)矩阵得到\(\boldsymbol{Q}\boldsymbol{K}^{\top}\),之后通过softmax获得一个根据相似度,该词应该放置多大的“attention”,输出的矩阵描述了query和key之间任意两个元素的关联强度(attention只负责计算空间相似度,实际的关联关系由之前使用的word embedding算法本身获得的向量的性质决定,比如使用word2vec可以将意义相近的词映射到向量空间相近的地方,则attention从词意上计算其相似度)。
- 之后将关联强度与V作矩阵乘法,就得到了神经网络“集中注意”后的输出值。由上文对矩阵乘法的理解,此处可以给出注意力权重与V相乘的过程在实际情况的理解:左边的矩阵的第i行第j列代表了一个句子中第i个词与第j个词的之间的关系大小;右边的矩阵则是整个句子的向量化矩阵,其中第i行表示第i个词。由矩阵与线性组合的理解,就可以看作一个词向量对应的输出结果是以该词与其他词的相似性作为系数的对应词向量的线性组合。可以看出,一个词与另一个词的含义如果越相似,那经过attention后另一个词对这个词的向量的影响就越大。
- 整个过程连起来解释就是:根据Q和K的相似度大小来决定V前的系数,从而输出V的一个线性组合。拿一个实际例子来看:我们现在有一个句子“我们是学生,我们热爱学习”,经过向量化后,在计算attention时(此处使用self-attention),我们发现“学生”和“学习”的相似度很高,于是重点关注了这句话的“学生”和“学习”两个词,达到了attention的目的。
self-attention
在attention的基础下很容易得出self-attention的运算过程。顾名思义,self-attention就是对自身的attention:
\[ Attention(\boldsymbol{X}\boldsymbol{W}_i^Q,\boldsymbol{X}\boldsymbol{W}_i^K,\boldsymbol{X}\boldsymbol{W}_i^V) \]
- 仅有自身的矩阵乘法不够灵活,所以在attention的基础下,对attention的每个输入前都加上了weight。
- 个人对self-attention的理解是:举例来说,比如在一个文本分类任务中,有一句话为:“读书能够使人学习到很多有价值的东西”。那么这句话的重点应该放在“读书”、“学习到”上。在我们尝试确定关注度时,我们是对这个句子本身进行分析后得出的结果,所以self-attention也是用这种方法来得出关注度的。按照苏剑林大师傅的话就是“在序列内部做Attention,寻找序列内部的联系”。
多头attention
- 类似于CNN的多核卷积捕捉不同信息,多头attention将多个attention拼接起来:
\[ head_i = Attention(\boldsymbol{Q}\boldsymbol{W}_i^Q,\boldsymbol{K}\boldsymbol{W}_i^K,\boldsymbol{V}\boldsymbol{W}_i^V) \]
\[ MultiHead(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = Concat(head_1,...,head_h)\boldsymbol{W^{\boldsymbol{O}}} \]
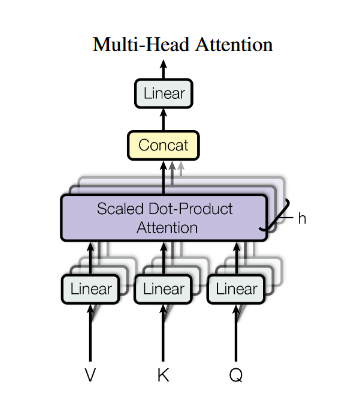
可以注意到,此处的“Q、K、V”都是加入权重后的Q、K、V。在网上有的文章中,将self-attention或多头attention中的Q、K、V与基础attention搞混了,直接带入X,得到类似\(Attention(\boldsymbol{X},\boldsymbol{X},\boldsymbol{X})\)的形式,这和原论文是有出入的。直接使用\(Attention(\boldsymbol{X},\boldsymbol{X},\boldsymbol{X})\)得到的结果只是类似于三个X直接连乘的计算结果,从数学表达式上看只取决于输入的向量,没有经过神经网络学习的权值,而多头attention中的形式是\(Attention(\boldsymbol{X}\boldsymbol{W}_i^Q,\boldsymbol{X}\boldsymbol{W}_i^K,\boldsymbol{X}\boldsymbol{W}_i^V)\),里面还包含了神经网络“根据实际情况灵活变化权值”的含义。
Positional Encoding
- 前面提到,attention模型本身是词袋模型,因为如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的(容易证明,矩阵任意两行交换顺序后自身与自身的转置相乘,得到的矩阵只是按行交换了顺序而已);说明self-attention结构本身是一个词袋模型。所以还需要一个加入位置信息的操作,不然就会遗失重要的顺序信息。所以在paper中,Transformer使用了Positional Encoding加入顺序信息。
具体操作如下(这里给出的是某个位置的向量的某个维度的映射过程):
\[ \left\{\begin{aligned}&PE_{2i}(pos,2i)=\sin\Big(pos/10000^{2i/{d_{model}}}\Big)\\ &PE_{2i+1}(pos,2i+1)=\cos\Big(pos/10000^{2i/{d_{model}}}\Big) \end{aligned}\right. \]
其中,pos为位置的序列,i是当前的维度;这样,就可以把整个向量组按位置重新映射成一个大小与整个矩阵相同的位置向量组。使用这个映射的原因是,因为有关系\(\sin(\alpha+\beta)=\sin\alpha\cos\beta+\cos\alpha\sin\beta\)和\(\cos(\alpha+\beta)=\cos\alpha\cos\beta-\sin\alpha\sin\beta\),所以如果两个向量存在位置相差,他们之间成线性关系,则可以更好地通过机器学习学习出这个关系(如在sin中,只用学习出sinα和cosα),这样就给学习位置信息打下基础。
以下是一个长度为20个词的句子经过PE得到的位置矩阵,每个词的维度为512,每个PE值范围在[-1,1];左侧是用sine函数生成,右侧是用cosine生成(本来应该交叉生成,由于Q、K、V矩阵的行可交换性,将左边右边分别批量计算):
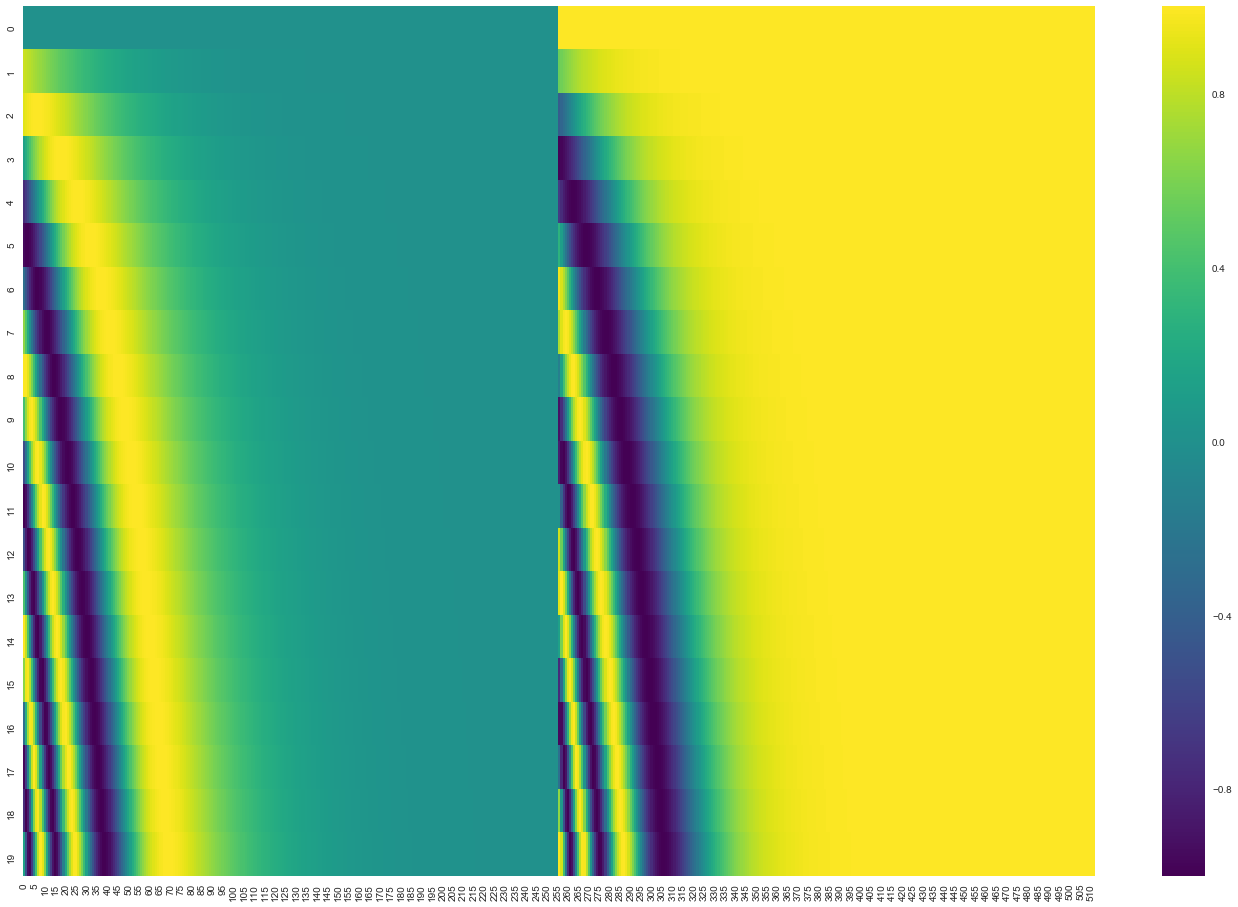
图片来自:https://jalammar.github.io/illustrated-transformer/
- 但是,PE这种硬编码并不能完美的表示位置信息,这也是Transformer模型的一个缺点。
Position-wise Feed-Forward Networks
- 在Transformer结构中还用到了FFN全连接网络(一个两层的全连接网络),计算过程如下(一个ReLu激活的全连接嵌套了一个线性激活的全连接):
\[ FFN(x) = max(0,xW1+b1)W2+b2 \]
attention效率分析
- 通过矩阵乘法,我们可以看出,attention在计算过程中与数据维度相关的复杂度为\(O(d^2)\)。而这个矩阵乘法本身则完成了一个句子中任意两个词之间关系的计算。可以预见,当数据的维度过高(句子很长)时,计算量会偏大。
Transformer
就Attention is All You Need这篇论文而言,它的核心在于提出了attention这个结构。而论文中同时也提出了Transformer模型,作为attention的第一个应用。
首先放图(一句话只有两个词的Transformer):
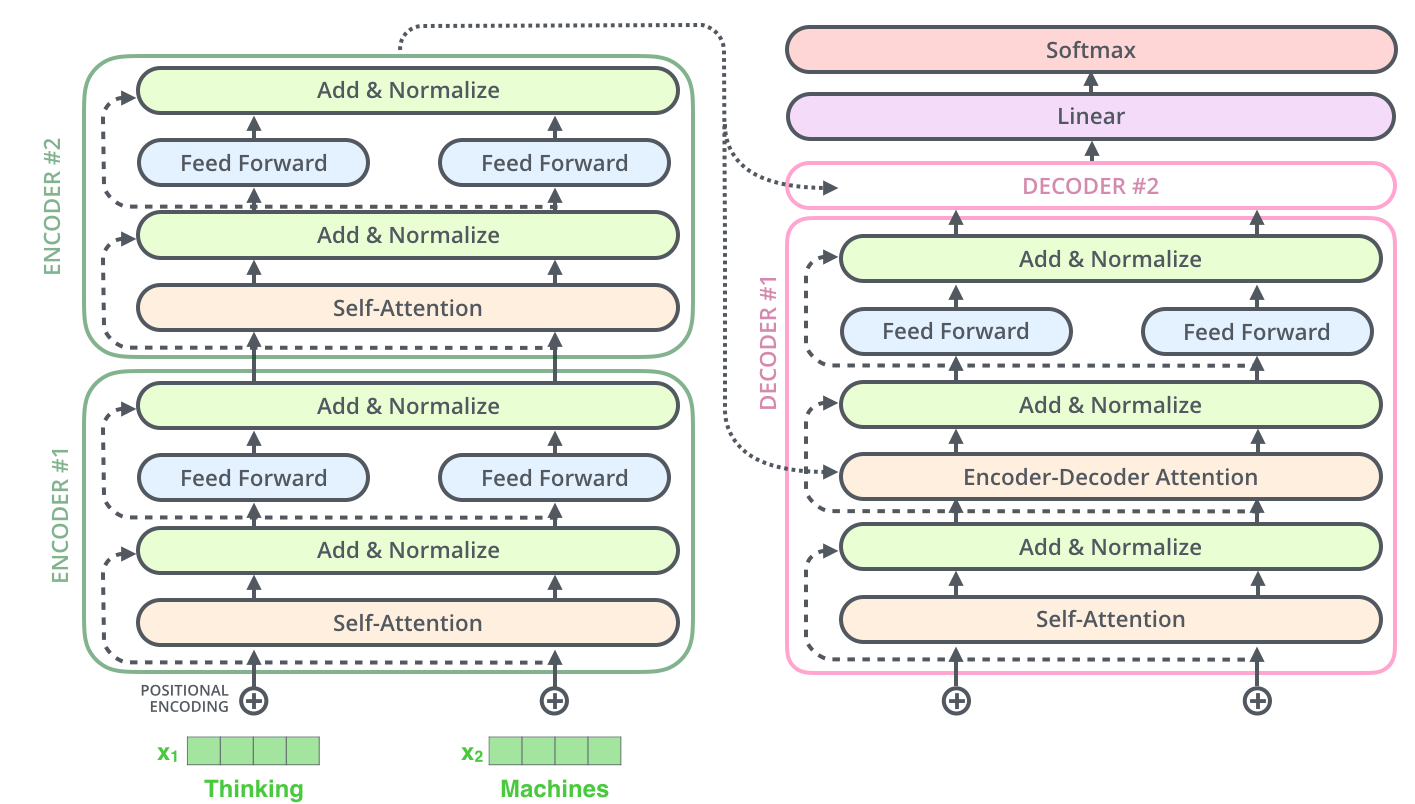 图片来自:https://jalammar.github.io/illustrated-transformer/
图片来自:https://jalammar.github.io/illustrated-transformer/- 在前文对多头attention、位置嵌入(PE)、FFN结构了解的基础和对seq2seq的了解上,可以比较容易的理解Transformer的结构。
Transformer是典型的encoder-decoder结构。
首先是encoder:
先定义一个结构:AN层:首先加上原数据,然后经过Layer Normalization处理;这里的AN层是一个残差操作,其思想跟深度残差网络类似(个人理解是原始数据是最重要的信息来源,在经过深层的神经网络处理后,虽然得到了特征提取,但原始信息有部分丢失,此时直接将原始特征相加后能够直接把原始信息引入深层次网络中)。
- 经过词向量嵌入之后,直接与PE相加,加入位置信息。
- 通过多头self-attention(此处多头加入权重对原始向量作出映射)后经过残差AN层,输入FFN(注意此处,每一个词都由单独的一个DNN处理,但实际上可以由一个拼接的DNN来处理,所以图中的两个Feed Forward可以由一个拼接的大DNN代替,参考),再经过AN层,这个结构重复N次。
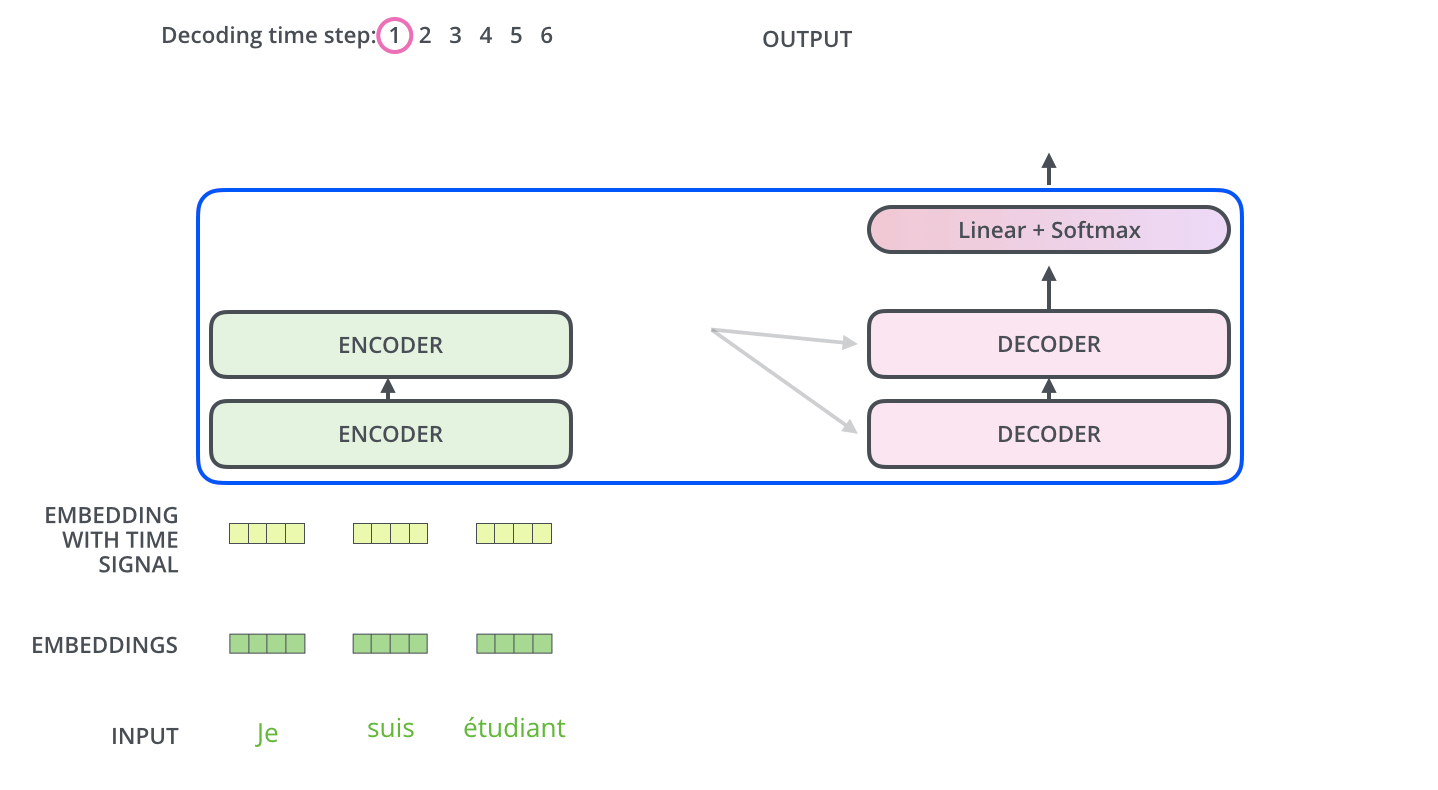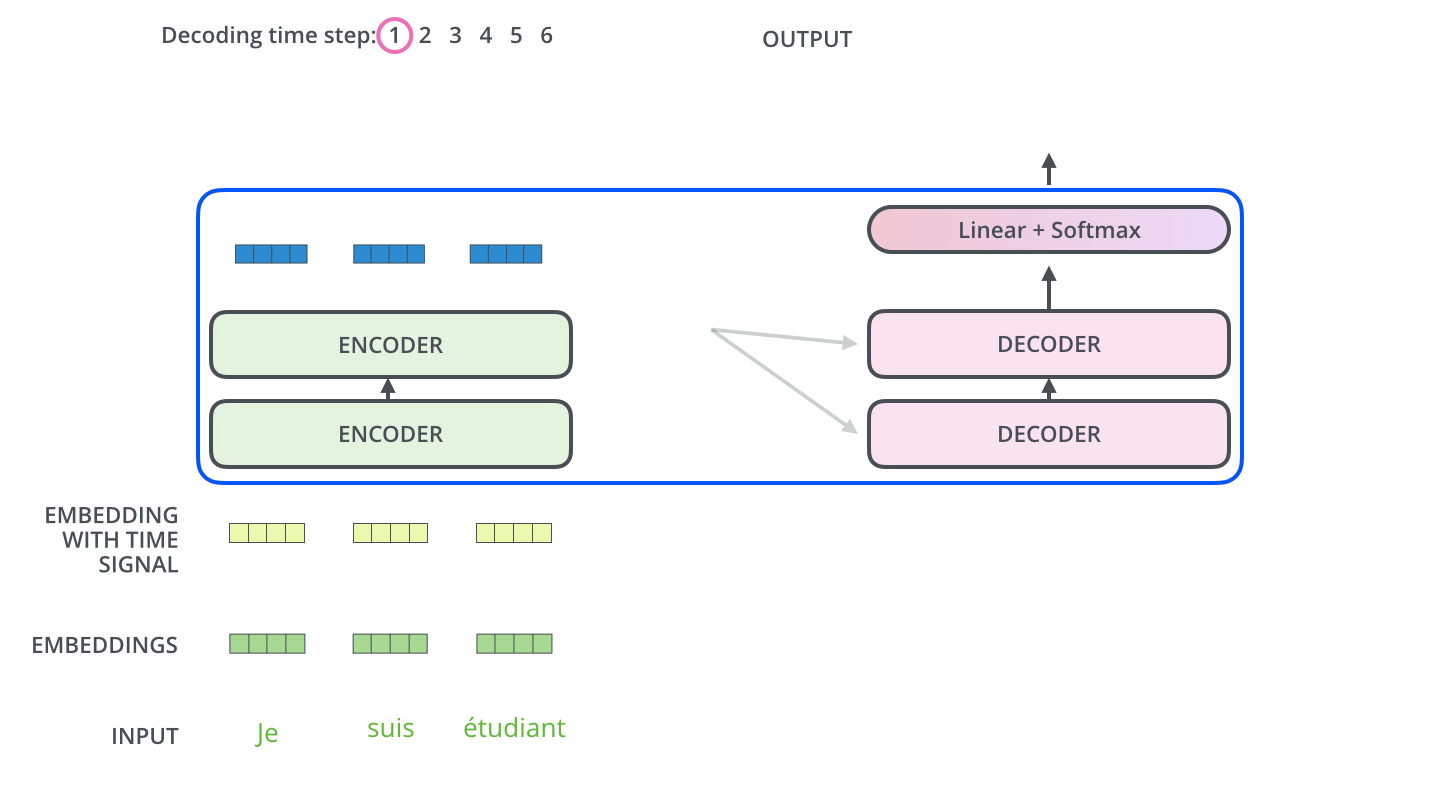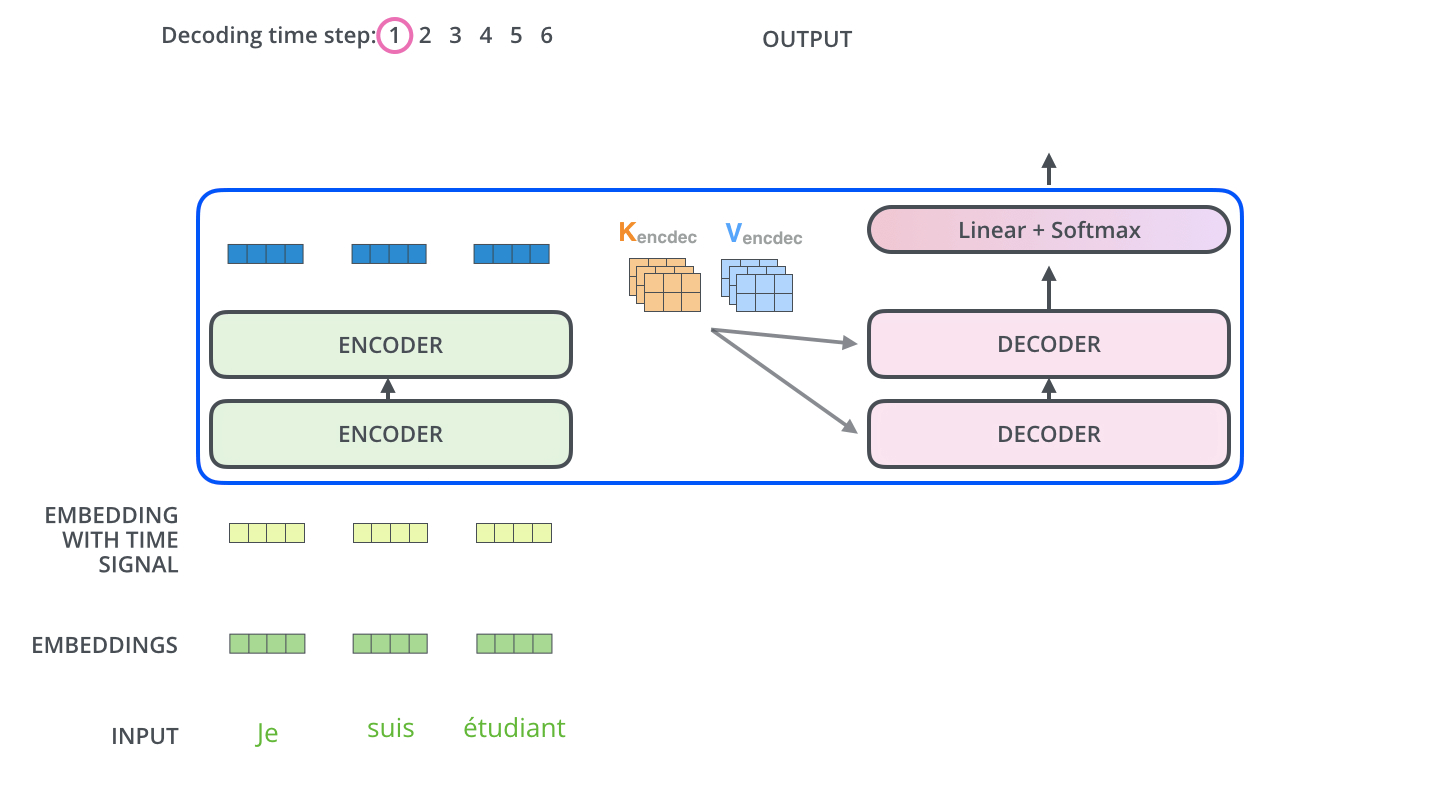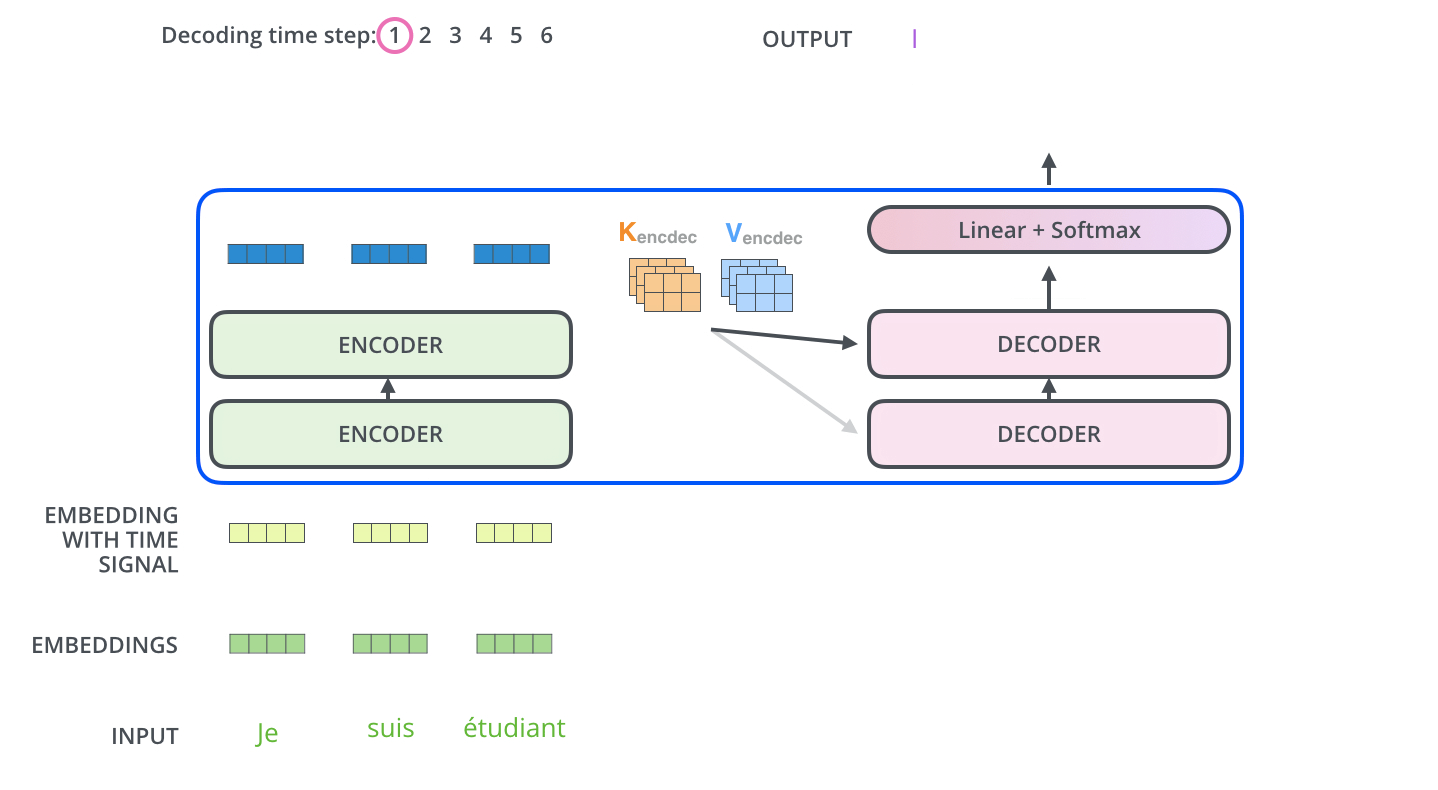
图片来自:https://jalammar.github.io/illustrated-transformer/
然后是decoder:
- decoder将已经翻译过的输出当作最初的词向量传入(比如已经翻译的“I am a”的词向量),这里的实现过程是,词向量“未来”的位置会被mask操作遮挡(将它们设置为-inf),从而保证每一步输入的词向量长度一致,但又有变长的信息作为输入,类似于一般的词向量对齐操作。
- 通过多头self-attention(此处多头加入权重对原始向量作出映射),经过残差AN层;再通过多头attention(此处多头加入权重对原始向量作出映射),不过,第二次attention从前层获取输出转成query矩阵,接收最后层编码器的key和value矩阵做key和value矩阵,再经过AN层;输入FFN层(与encoder同样的,每一个词都由单独的一个DNN处理,但实际上也可以直接由一个拼接的长DNN处理),再进入AN层。这个结构重复N次。
- 最终通过线性全连接层和softmax输出当前翻译词语是字典中每个单词的概率。

图片来自:https://jalammar.github.io/illustrated-transformer/
- 在训练时,最基本的LOSS函数是最终的softmax与准确的词语的onehot之间的交叉熵。网上也有其他更复杂的结构,比如先输出最高概率的位置,再经过一层神经网络输出最终结果。
一些个人想法
- attention结构的关键词是“相似度”和“关注度”,即根据相似度大小确定关注度。
- 由于attention可以计算不同词之间的关系,在其输出中已经包含了“上下文”的含义,可以在一定程度上解决“一词多义”的问题(可以比较容易的证明:同一个词语在不同的句子中,经过attention操作后得到的向量是不一样的)。
- 比较重要的问题是“词袋模型”问题和“一词多义”问题。
bojone版本attention与原论文的“不一致”
- 在bojone实现的attention中,PE编码直接将前半段使用cos处理,后半段使用sin处理;原文则使用sin和cos交叉的方式。
具体的issue有https://github.com/bojone/attention/issues/2、https://github.com/bojone/attention/issues/5、https://github.com/bojone/attention/issues/11。作者给出的解释是attention的行是可以任意打乱顺序的,因为它本身就是词袋模型。 - 在这里,我个人更偏向于按原文方式进行PE,我给出的理由是:加入PE的句子不再是词袋模型,而PE本身的计算顺序就和位置密切相关。在bojone的观点下,PE的顺序是不重要的,即把PE按行打乱顺序对结果是没有任何影响的。这可能并不正确,由图像“positional_encoding”可以看出,PE的计算过程中,每个行打乱顺序后效果并不一致,并且这些交替的顺序中本身可能就蕴含了时序关系。(都是个人感觉)所以在使用bojone版本的attention时我倾向于忠实原文的方法。